
Solr Tutorial
I recently had the need to search a large amount of online auction data. I had access to the data associated with a large number of online auctions, similar to auctions on eBay. I needed to quickly find auctions whose title and description match a given set of search terms. My solution was to use Solr, an open source search application/platform. This post describes the steps I carried out to set-up Solr, and the difficulties encountered along the way. The post covers Solr 4.8.
The decision to use Solr was based on the need for a fast and customisable mechanism to search for auctions. Initially, MySQL’s fulltext search was used. This was slow, inflexible and had a number of issues such as not recognising numbers or common words.
Overview of Solr operation
Solr behaves in many ways like a web server such as Apache: once started, Solr uses the data in its installation directory to serve responses to client requests. The major difference is that Solr is serving search results (in XML, JSON or other formats) as opposed to web pages. The Solr installation is completely standalone: the Solr directory contains everything needed to start and run the server, including a Java Servlet container and all the application data. Solr is controlled using configuration files. Four files in particular play an important role:solr.xml, solrconfig.xml, schema.xml and solr-data-config.xml (schema.xml and solr-data-config.xml can have custom names).
Starting Solr
To start Solr in its default state, navigate to:
apache-solr-X.X.X/example/
and run:
java -jar start.jar
This starts the server and sets Solr to use the default home directory, ./solr.
When making your own Solr instance, it is a good idea to start by copying the default Solr directory, name it as you wish, and start working with this new Solr instance.
Assuming I call my Solr directory AuctionSearch, to start Solr after making the new directory, run:
java -jar start.jar -Dsolr.solr.home=AuctionSearch
After running this command, you can browse to http://localhost:8983/solr/ to view the administration user interface. The default Solr instance doesn’t have any documents indexed (or it might have just one), so there wont be much to tinker with until more documents are added. Before adding documents, however, some configuration will probably be needed.
Configuring Solr
Configuring Solr is not typically done once- instead a cycle of configuring and testing is carried out. Even months after I initially set up Solr to work for my application, I am still tweaking it as I learn more about Solr and learn more about my data. Despite this cyclic nature, the configuration of Solr will be described here in a linear fashion. However, jumping between sections is encouraged. In turn, the following will be discussed:
solr.xmlSolr coresschema.xmlDocument structuresolrconfig.xmlRequest handlers
When configuring Solr, it is helpful to have a picture of the Solr home directory structure, and to know where all the configuration files are located. The image below shows important configuration files within the example Solr directory.
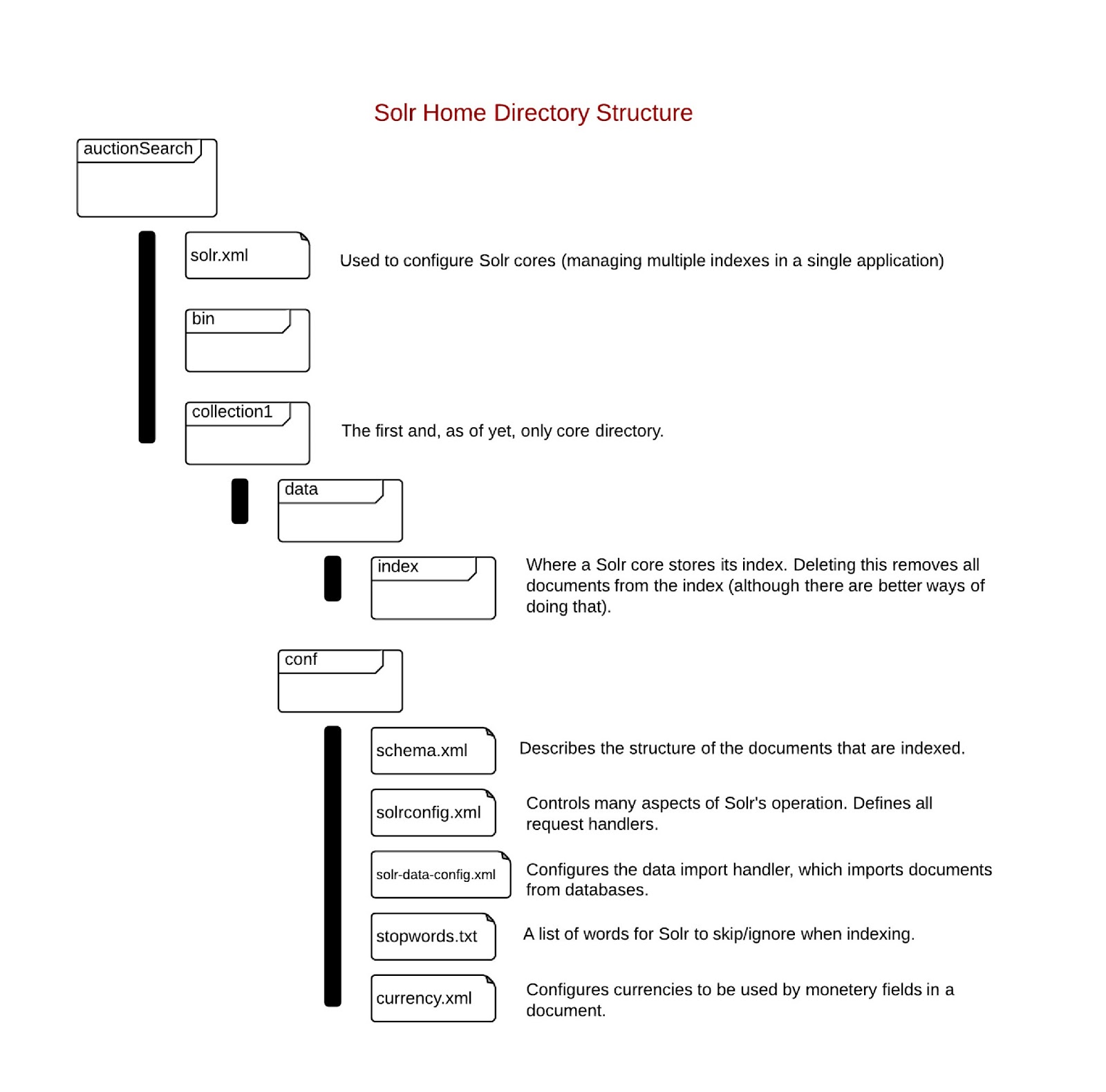
Solr cores
A Solr core manages a single index. An index is the set of all data used to store information about documents to be searched. Each index can have only one document schema associated with it (only one document format can be stored). Using multiple cores allows a single Solr instance (single server, single administration web page) to manage multiple indexes. A use case (context: auction website) for this might be having one core for indexing auction data and another for indexing information on users. Each core will have its own core directory.
Cores are configured in solr.xml. An example solr.xml:
1 2 3 4 5 6 | |
Usually, the default solr.xml is sufficient. You may want to change the core names and core directory names. Further details on configuring solr.xml.
In Solr 4.3 and above, solr.xml has a new purpose and a new format. In Solr 5.0 and above, the older format will not be supported.
Schema
A Solr schema describes the basic unit of information: a document. Each Solr core has a single schema, and thus, indexes only one ‘form’ of document. A document is composed of multiple fields. Each field has a type. This type is defined in the schema and specifies the underlying Java class that is created when the field is indexed. The type also specifies the text analysis (processing/digestion) that is carried out when the field is indexed. An example document and a section of the corresponding schema.xml is shown below.
1 2 3 4 5 6 7 8 9 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
The components of schema.xml will now be described.
Fields
A field describes a piece of information within a document. It controls aspects of the indexing process such as what Java type is used to represent the data, whether the data is stored, whether the field is required in every document etc. There are two types of special fields: copyField and dynamicField (not to be confused with the type parameter such as type=”string”).
- copyField
- Copy fields allow you to index a field in more than one way. A field is copied allowing different field types, such as
text_enorstringto be applied to the single piece of information. - dynamicField
- Dynamic fields are, in a way, an inverse to copying fields; they allow you to process multiple fields in the same way. Their most useful feature is their ability to match document fields with pattern matching. A common usage of dynamic fields is to catch all fields in a document which should not be indexed. This is required, as when fields are indexed, all document fields must be processed, or an error is thrown.
An example of using copy and dynamic fields is show below:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Analysers, tokenisers and filters
Each field has a type, and each type is defined by a set of analysers (which are made up of tokenizers and filters).
- Analyser
- An analyzer converts the text of a field and modifies it to form the
text that is indexed. Analyzers are made up of one or more tokenizer
and/or filter. Seeing as analyzers are
constructed from filters and tokenizers in an adhoc manor, they don’t
really have a name; they will just be identified by the
fieldTypewhere they are defined. - Tokenizer
- A tokenizer breaks up a stream of text into units, called tokens. For example, the text: “Please like my blog”, might be passed through a filter to produce the 4 tokens: (Please, like, my, blog) or using another type of tokenizer: (p, l, e, a, s, e, l, i, k, e, m, y, b, l, o, g).
- Filter
- Filters take in tokens, transform them, and output the transformed tokens (they can modify or discard them). A example: a filter which converts all text to lowercase.
A useful note: analyzers can operate both at index time and at query time. In other words, they transform both the documents that are indexed and the search terms that are used by a user.
A reasonably complex analyzer is shown below. It is defined in the example Solr schema.xml file for the fieldType text_en:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
Schema snares
There are two issues I encountered when creating a schema for which I had trouble finding information online. Consider coming back to this section if you have issues.
Multivalued fields
Multivalued refers to the possibility of their being two values for present in the same document for a single field. For example, for the document shown below, there is always only one title. An example of a multivalued field is the feature field, this can have many values in a single document. What is important to realise when using multivalued fields, is that the data gets flattened. If an auction has 2 features, then the two features get flattened such that the relationship between the name and the value of the feature is lost.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
By observing the way the data is indexed, it is clear that the relationship between the name and value pairs is lost. In other words, one to many relationships cannot be maintained by Solr in a single index (the is an exotic method of using multiple indexes and multiple cores). From a relational database point of view, Solr flattens all data into a single ‘table’.
PolyFields
A ployfield, such as the Currency field, is a field that requires more than one value to be stored when it is indexed. The currency field needs to store both the amount of money and the currency of the money. Polyfields must have stored=true, or errors will result.
solrconfig.xml
solrconfig.xml is used to configure many aspects of Solr’s operation, for example, it is used to configure:
- request handlers
- listeners (listen for requests sent to handlers)
- admin interface
- replication and duplication
Typically, the only changes that need to be made to solrconfig.xml are to add or alter search and index request handlers. These two examples will be covered in the Indexing and Searching sections respectively.
Indexing data
There two difficult issues I encountered for which it can be hard to uncover the cause of the problem. This section can be skipped and returned to if issues arise.
There are two ways I have used to add documents to an index: posting XML to a request handler or importing it from a database. All the data I index is also stored in a database. I initially carry out a data import from a database to catch up on the database from an empty state. Once this import is finished, new documents are added to the index by sending the documents in XML form to Solr via HTTP post.
Importing from a database
Importing data from a database in carried out using the Data Import Handler
(DIH). To use the DIH, a configuration file must be created to direct
the conversion. In addition to the configuration file, a request handler must be specified in solrconfig.xml for the DIH. The details of writing the configuration file is given in the above link.
Posting XML
Once Solr has indexed the entire database, new documents are added by posting them to a Solr request handler. SolrJ, a Java API for Solr, is used to do the posting. Solr comes with a simple request handler for adding documents by posting XML. It is defined in solrconfig.xml as follows:
1 2 | |
Thus, by sending XML to the URL http://localhost:8983/solr/coreName/update, Solr will add the document to the index. Unfortunately, in most situations, if you already have XML data which you want to index, it probably wont exist in the format that Solr expects. For example, compare the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Thus, there is a need to convert the original XML into the form which Solr expects. There are two ways to do this conversion:
- In Java: JAXP API can be used to carry out the conversion. This will require writing custom code to do the conversion. Alternatively, if your data exists as Java classes, you can index those through SolrJ, which has a persistence mechanism allowing Java objects to be indexed directly.
- Use XSLT: Configure the Solr request handler to transform the posted XML using a specified XSLT before trying to index the document. An XSLT file to transform an XML document (with root XML element ‘Auction’) is shown below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
Indexing snares
There are two issues I encountered for which I had trouble finding information online. Consider coming back to this section if you have issues with indexing or the DIH, and you might be in luck.
Letter case in the DIH configuration file
Table and row names in the DIH configuration file are tediously case-sensitive-ish. Some places the case doesn’t matter, and other places it does. Where it does matter, the table and row names must be in the exact same form as in the database. Also, case must be internally consistent within the configuration file for most name usages.
Missing fields in posted XML and DIH mapping everything to the ignore field
These two seemingly unrelated issues are linked by the presence of a dynamic field in schema.xml. When posting XML data, all fields defined in the schema file must be present in the XML file being posted. If there are fields in the XML document which are not used in the index, errors are throw when posting the XML. The way around this is to create a catch-all field:
this schema field catches all fields in the document which have not been mapped to another field. This workaround, however, interferes with the operation of the DIH. The DIH, annoyingly, maps nearly all fields to the catch-all field. This may have something to do with the nice feature of the DIH which allows you to leave out every mapping from row->field if the row and field have the same name. Leaving out these mappings, however, seems to cause all fields to map to the catch-all ignore field. My current hack involves changing the schema.xml file every time I want to import documents using the DIH.
Searching
Search requests are carried out by request handlers which parse and process searches. A good way to describe search handlers is through an example. The following is a search request handler I use:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
All these parameters can be specified at query time also; defining them within the request handler definition simply specifies defaults. To use this search handler I would navigate/send request to:
http://localhost:8983/solr/auctions/broadQuery?q=dell+monitor+IPS
(Assuming that ‘auctions’ is the name of your Solr core, and Solr is hosted on localhost)
While most of the search handler’s configuration can be understood from the comments, defType, pf, ps and mm might need further explanation:
- defType
- defType specifies the search parser to use. There are a number of popular search parsers including Standard Search,DisMax and eDisMax. eDismax combines the features of both the Standard Search and DisMax; eDisMax supports the full query syntax of the Lucene Standard Query, but is far more tolerant of syntax errors. eDismax seems like the obvious choice in most circumstances.
- pf
- pf (phase fields) specifies what fields should be checked for having matching ‘phrases’. If matching terms are close enough together, then they can be considered a phrase. A result with a matching phrase will score higher than one with no matching phase. You can also specify a weighting: a field weighting will control the effect of a match on the match’s score. For example, a phrase found in the title will score higher that one found in feature.
- ps
- ps (phrase slop) specifies how many terms can be in-between two matching terms and still allow the matching terms to be considered a matching phrase.
Searching from Java
Searching can be carried out from Java with the use of SolrJ. The gist below shows a very simple method utilizing SolrJ:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Further reading
I have briefly covered many common tasked carried out when using Solr. There are many more features: search faceting, search clustering, distributed searches and index replication to name a few. There are many comprehensive sources available. Some useful sources I would suggest:
- Solr in Action
- Lucid Works’ Solr Reference Guide
- Taming Text (practical guide for all types of text searching and manipulations)
- Lucene in Action, 2nd Edition (if you want to go to a lower level than Solr)
- Tika in Action (if you want to index and search documents such as PDFs)